Part 1 — Why Standard RAG Fails in Production
What exactly breaks, and why, when you scale a naive RAG system to real enterprise data?
7 min · Updated July 2026
Two things people conflate. Hallucination is structural — a property of how the model generates. Retrieval failure is an engineering problem you can fix. This series is about the second. Getting retrieval right is what stops the first from mattering.
1.1 The fundamental LLM problem
Large language models are extraordinary at generating text that is coherent, fluent, and contextually appropriate. They are deeply unreliable at knowing facts. Their knowledge is frozen at a training cutoff. They have no access to your organisation’s internal documents. When they encounter a question whose answer lies outside their training distribution, they do the most dangerous thing possible: they answer anyway, confidently, in fluent prose. This phenomenon — hallucination — is not a bug that will be patched away. It is a structural property of how autoregressive language models work.
For consumer applications, hallucination is annoying. For enterprise applications — legal analysis, medical decision support, financial research, engineering compliance — it is a liability. A wrong figure in a consumer chatbot is a shrug; a wrong figure in a financial memo or a compliance filing is a legal exposure. The system must be grounded in your documents, your data, with claims traceable to your sources.
1.2 The first-generation RAG response
Retrieval Augmented Generation (RAG) was the first serious answer: instead of asking the LLM to generate from parametric memory alone, retrieve relevant context from a knowledge base and give it to the LLM before generating. The LLM becomes a synthesizer and reasoner over supplied evidence rather than a source of facts.
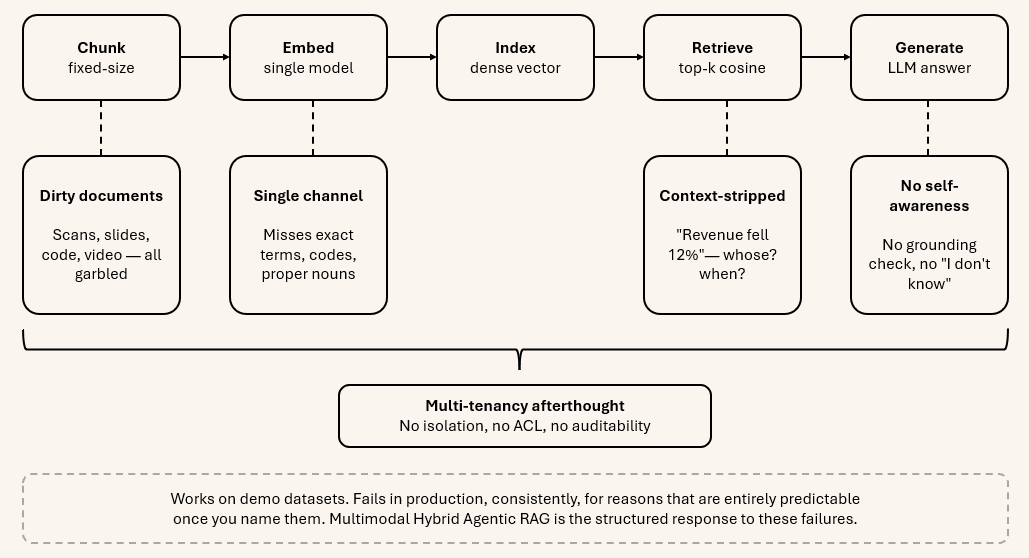
First-generation RAG achieved this through a simple three-step pipeline: chunk documents into fixed-size pieces, embed them with a single embedding model into a dense vector index, and at query time retrieve the top-k nearest chunks by cosine similarity, then pass them to an LLM.
Here is the entire thing. It’s worth building once, because everything in the rest of this series is an improvement on one of these lines:
# First-generation RAG — the baseline that fails in production.
from langchain.text_splitter import CharacterTextSplitter
from langchain_openai import OpenAIEmbeddings, ChatOpenAI
from langchain_community.vectorstores import FAISS
# 1. Chunk at a fixed size — no awareness of headings, tables, or sections.
chunks = CharacterTextSplitter(
chunk_size=512, chunk_overlap=0
).split_text(raw_text) # ← strips document structure
# 2. Embed with ONE model into ONE dense index.
store = FAISS.from_texts(chunks, OpenAIEmbeddings()) # ← single point of failure
# 3. Retrieve top-k by cosine similarity, then generate. Always.
def answer(query: str) -> str:
top_k = store.similarity_search(query, k=4) # ← semantic-only recall
context = "\n\n".join(c.page_content for c in top_k)
prompt = f"Context:\n{context}\n\nQuestion: {query}"
return ChatOpenAI(model="gpt-4o").invoke(prompt).content # ← no grounding checkThis works. On demo datasets. With clean, digital, single-modal, English-language documents. In controlled evaluations. In a single-tenant setting. Without adversarial queries.
It fails in production, consistently, for reasons that are entirely predictable once you name them — and each maps to a specific line above.
1.3 What first-generation RAG gets wrong
For each failure below, the italic Symptomline is what you’ll actually observe in your own system. If you recognise it, you’ve found your bottleneck.
The documents are not clean digital text. Enterprise knowledge lives in scanned PDFs with misaligned columns, PowerPoint decks with text in image layers, video recordings of design reviews, spreadsheets with merged cells, code repositories, and HTML pages with JavaScript-rendered content. A naive chunker that splits every document at 512 characters destroys structure that took years to create.
Symptom: retrieval quality collapses on exactly the documents that matter most — the scanned contract, the slide with the architecture diagram — while working fine on the clean wiki pages you demoed with.
A single embedding model is a single point of failure. Dense vector similarity retrieves semantically similar text. It routinely misses documents containing exact technical terms, product codes, legal statute references, or proper nouns that embeddings map to the same region as dozens of unrelated concepts. Conversely, BM25 keyword retrieval has excellent exact-match recall but zero semantic generalisation. Neither alone is sufficient.
Symptom: a user searches for error code TS-4491 and gets back generic troubleshooting chunks — never the one page that actually names the code.
Fixed-size chunks strip context. A chunk reading “revenue declined 12% quarter-over-quarter” is meaningless without knowing whose revenue, which quarter, which product line. Extracted from a 300-page annual report and retrieved in isolation, it is actively dangerous — a plausible-sounding figure that may answer a completely different question. Compare:
Retrieved chunk (naive):
“...revenue declined 12% quarter-over-quarter...”
Same chunk, context-enriched:
[Doc: FY25 Annual Report · §4.2 EMEA Hardware · Q3 2025]
“...revenue declined 12% quarter-over-quarter...”The second is answerable; the first is a landmine. That difference is metadata the naive chunker threw away.
Symptom: answers are confidently wrong — a real number from your corpus, attached to the wrong entity or period.
A pipeline has no self-awareness. Once a naive RAG pipeline retrieves and generates, it is done. It cannot tell whether what it retrieved was relevant. It cannot tell whether what it generated is grounded in the retrieved context. It cannot route a multi-hop question to a different strategy. It cannot decide that the corpus simply does not contain the answer and return “I don’t know.” It just generates, every time, from whatever it retrieved.
Symptom: the system never says “I don’t know” — even when the answer isn’t in the corpus, it fabricates one from the nearest four chunks.
Scale and multi-tenancy are afterthoughts. First-generation RAG treats the knowledge base as a single, globally-accessible repository. Enterprise systems have tenants with strictly isolated data, users with role-based access to specific document sets, compliance requirements that mandate auditability, and corpora that reach hundreds of millions of chunks.
Symptom: it works for one team, then leaks tenant A’s documents into tenant B’s answers the moment you onboard a second customer.
Multimodal Hybrid Agentic RAG is the structured response to every one of these failures.
1.4 The failure-to-fix map
Every failure above has a known remedy and a dedicated part of this series. This table is the spine of the whole thing — each later part picks one row and goes deep.
| Naive failure | What you’ll see | Fix category | Tools | Covered in |
|---|---|---|---|---|
| Dirty documents | Quality collapses on scans & slides | Layout-aware parsing | Unstructured, LlamaParse, Docling | Part 3 |
| Single embedding | Misses exact codes & proper nouns | Hybrid retrieval | BM25 (rank_bm25 / OpenSearch), Qdrant, Weaviate, Vespa | Part 4 |
| Context-stripped chunks | Right number, wrong entity | Context-aware chunking | Parent-document retrieval, metadata enrichment | Part 5 |
| Pipeline blindness | Never says “I don’t know” | Agentic orchestration | LangGraph, LlamaIndex agents, Cohere Rerank, bge-reranker | Part 6 |
| No multi-tenancy | Tenant A leaks into tenant B | Tenant isolation | Qdrant / Weaviate native tenancy, RBAC, audit logging | Part 7 |
1.5 Score your own exposure
Before reading on, a 30-second self-audit. Count your “yes” answers:
- 1.Does your corpus include scanned PDFs, slide decks, or spreadsheets? Y / N
- 2.Do users ever search by exact code, SKU, or statute reference? Y / N
- 3.Could a retrieved chunk be ambiguous without its parent section? Y / N
- 4.Does your system ever need to answer “I don’t know”? Y / N
- 5.Will more than one team or customer share the same index? Y / N
Three or more “yes” answers means naive RAG will fail you in production — the only question is which failure surfaces first. Multimodal Hybrid Agentic RAG is the structured response to every one of them, and the rest of this series builds it one row of the table at a time.